The Shared Memory layout of Blackwell MMAv5 operands
The 5th gen Tensor Core on Blackwell GPU requires MMA’s operand B live in SMEM, and operand A live in SMEM or Tensor Memory (TMEM). MMAv3 (Hopper) supports “SS_GEMM” as well where A and B are both in SMEM. The layout is almost the same as v5.
In this note we analyse the SMEM layouts and examine how CUTLASS and Triton represent them. The non-swizzling cases need special handling and omitted for simplicity in this note. We also only talk about 16B atomicity swizzling for simplicity.
Core Matrix vs Swizzle Atom
Core Matrix
“Core matrix” is a deprecated term and no longer available in official documents. It used to be a term used to help
define Leading Dimension Byte Offset (LBO) and Strided Dimension Byte Offset (SBO), which are two very important
parameters required to supply SMEM layout representations to hardware such that Tensor Core knows where to find operands.
For example, in this Colfax tutorial,
Each core matrix has a strided direction and a contiguous direction, such that its length is 8 in the strided direction and 16 bytes in the contiguous direction. LBO (leading dimension byte offset): the distance, in bytes, between two adjacent core matrices in the K dimension. SBO (stride dimension byte offset): the distance, in bytes, between two adjacent core matrices in the M or N dimension.
which might be correct to that specific instance of MMA in the blog, but doesn’t cover MN-major cases.
As can be seen later in this note, the concept of core matrix is indeed no longer needed. And we only need Swizzle Atom to define SBO and LBO.
Swizzle Atom
As of Jun 2026, the official PTX documentation defines the SMEM layout with the concept of “Swizzle Atom”.
A Swizzle Atom with s Bytes swizzling mode is a matrix of 8 * s Bytes where 8 is on the strided dimension
(e.g. M/N dim for K-major) and s Bytes is on the leading dim.
All the elements in a Swizzle Atom are compactly stored in a segment of contiguous physical SMEM. The SMEM swizzling then wouldn’t “exchange” elements across two Swizzle Atom. It’s only inside one Swizzle Atom. Also note the basic unit of swizzling is 128 bits or 16 bytes (in 16B atomicity mode). No “exchange” happens inside a single unit.
SBO is then defined as the byte offset between two adjacent Swizzle Atoms on strided dim.
LBO is defined as the byte offset between two adjacent Swizzle Atoms on leading dim. Note for K-major LBO is ignored because it’s “not used, assumed to be 1” in PTX doc.
Triton
In Triton compiler there’s a function called getCoreMatrixLinearLayout. It’s in fact getting a Linear Layout tile of a Swizzle Atom despite the naming. Since Linear Layout incorporates swizzling, the output of this function already encodes the full swizzled layouts of such an Atom. e.g.
Full tensor shape: 128, 256
Layout encoding: #ttg.nvmma_shared<{swizzlingByteWidth = 128, transposed = false, elementBitWidth = 16}>
getCoreMatrixLinearLayout output:
- offset=1 -> (0, 1)
offset=2 -> (0, 2)
offset=4 -> (0, 4)
offset=8 -> (0, 8)
offset=16 -> (0, 16)
offset=32 -> (0, 32)
offset=64 -> (1, 8)
offset=128 -> (2, 16)
offset=256 -> (4, 32)
where out dims are: [dim0 (size 8), dim1 (size 64)]
SMEM Layouts for an MMA instruction
The PTX documentation records canonical CUTE layouts for the SMEM tensor of one single MMA instruction:
| Major- ness | Swizzling mode | Canonical Layout without swizzling | Swizzling on the previous column |
|---|---|---|---|
| MN- major | No-swizzling or Interleaved | ((T,1,m),(8,k)):((1,T,SBO),(1T,LBO)) | Swizzle<0, 4, 3> |
| 32B Swizzling | ((T,2,m),(8,k)):((1,T,LBO),(2T,SBO)) | Swizzle<1, 4, 3> | |
| 64B Swizzling | ((T,4,m),(8,k)):((1,T,LBO),(4T,SBO)) | Swizzle<2, 4, 3> | |
| 128B Swizzling | ((T,8,m),(8,k)):((1,T,LBO),(8T,SBO)) | Swizzle<3, 4, 3> | |
| K- major* | No-swizzling or Interleaved | ((8,m),(T,2k)):((1T,SBO),(1,LBO)) | Swizzle<0, 4, 3> |
| 32B Swizzling | ((8,m),(T,2k)):((2T,SBO),(1,T)) | Swizzle<1, 4, 3> | |
| 64B Swizzling | ((8,m),(T,2k)):((4T,SBO),(1,T)) | Swizzle<2, 4, 3> | |
| 128B Swizzling | ((8,m),(T,2k)):((8T,SBO),(1,T)) | Swizzle<3, 4, 3> |
- T = 128 / sizeof-elements-in-bits T represents scale factor which normalizes matrix element types to 128-bits.
- m represents the number of repeating patterns across rows.
- k represents the number of repeating patterns across columns.
* As shown later in this note, the factor k in K-major layout is in fact not needed and should be dropped.
MN major
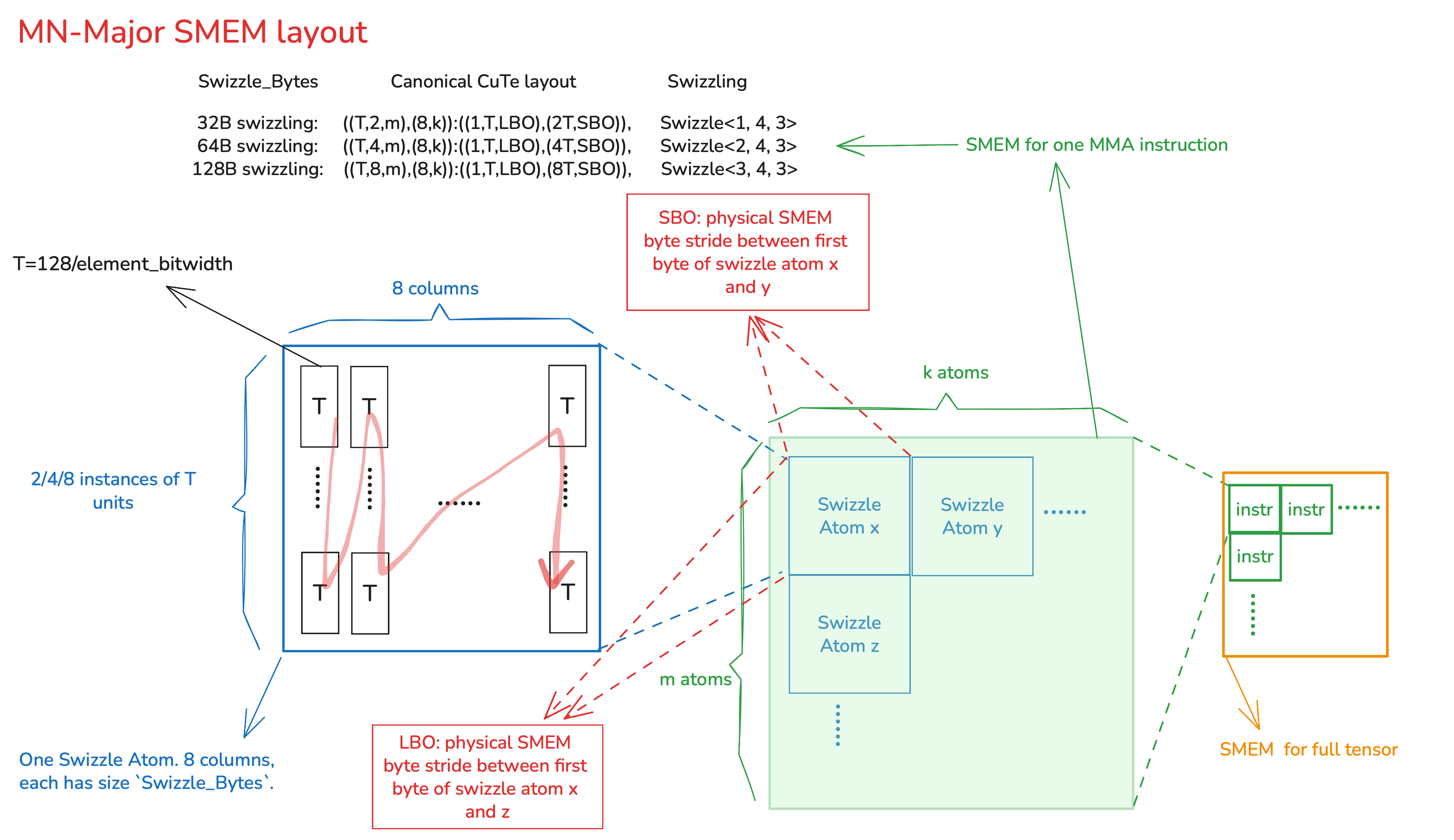
(The figure is drawn as M/N x K following CUTLASS convention)
The Canonical CuTe layout in PTX documentation is consistent with CUTLASS, and is shown in the figure.
Inside a Swizzle Atom, there’re 8 columns that’re adjacent to each other on physical memory. Each column is a contiguous segment on physical memory and has size equal to swizzling byte width.
It’s up to the user how to distribute the Swizzle Atoms(along MN or K dim first). As long as LBO and SBO are provided, the hardware knows where in the physical memory to look for desired Atoms. Note both LBO and SBO are needed because hardware needs to know where on the physical memory to load Swizzle Atom y, z and others.
From the getCoreMatrixLinearLayout function above, Triton always distributes the Atoms along strided dim first up to a
TMA block.
K major
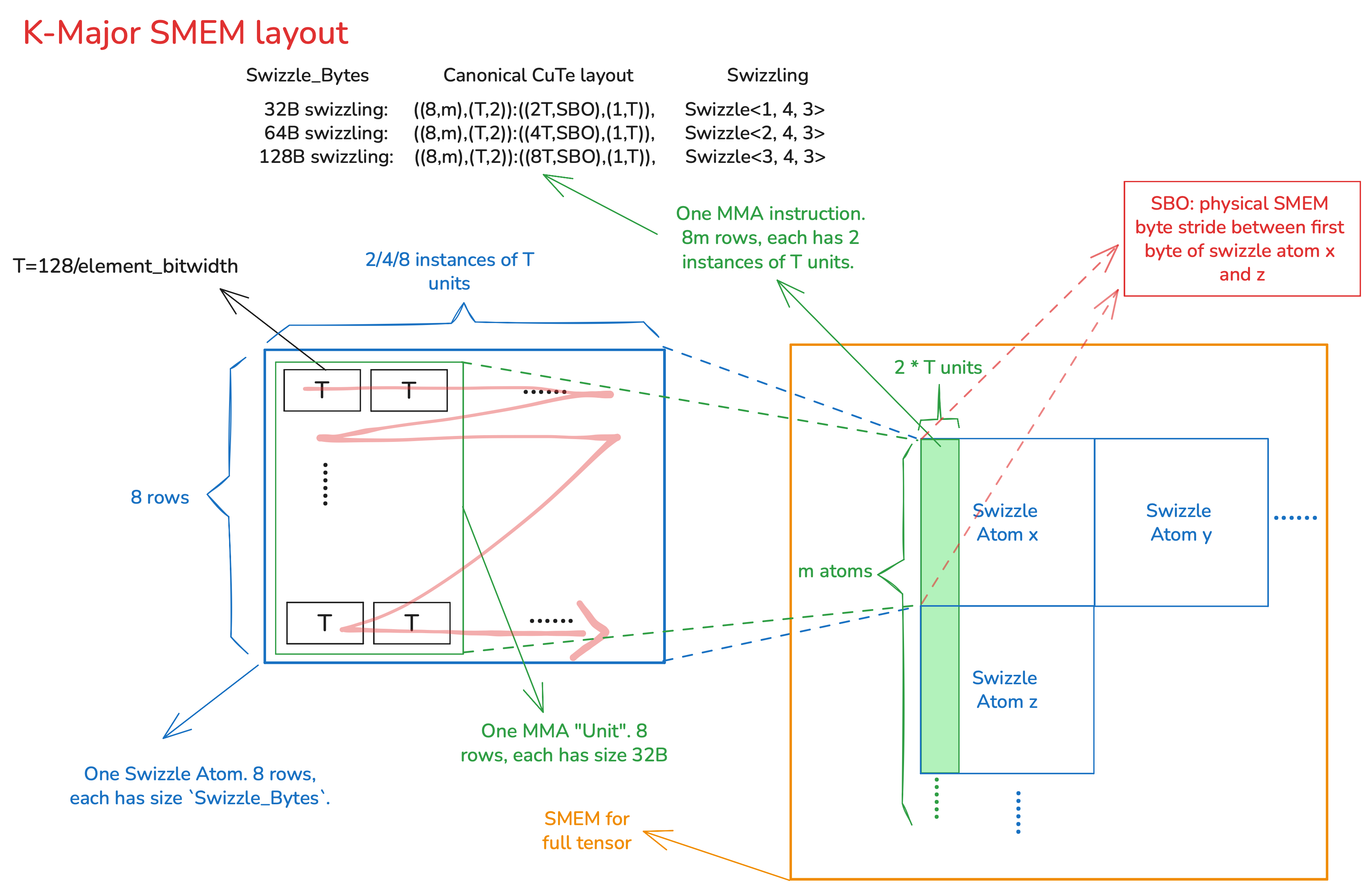
The Canonical CuTe layout in PTX documentation is different from CUTLASS in that CUTLASS dropped factor k. We adopt
CUTLASS’s layouts as the source of truth with confirmation from Nvidia.
Inside a Swizzle Atom, there’re 8 rows adjacent to each other on physical memory. Each row is a contiguous segment on physical memory and has size equal to swizzling byte width.
It’s up to the user how to distribute the Swizzle Atoms(along MN or K dim first). For 64B/128B swizzling, an MMA “unit” SMEM is smaller than a Swizzle Atom and each row in a Swizzle Atom contains elements from 2/4 different MMA instructions. This is OK because swizzling just deterministically tells hardware the exact location of each element. e.g. For 128B swizzling this table shows where in the physical SMEM to find the 8*2 T units of the first MMA instruction:
| Physical Offset | 16B | 16B | 16B | 16B | 16B | 16B | 16B | 16B |
|---|---|---|---|---|---|---|---|---|
| 0 ~ 127B | 0 | 1 | ||||||
| 128 ~ 255B | 3 | 2 | ||||||
| 256 ~ 383B | 4 | 5 | ||||||
| … | 7 | 6 | ||||||
| 8 | 9 | |||||||
| 11 | 10 | |||||||
| 12 | 13 | |||||||
| 15 | 14 |
Each MMA instruction’s SMEM operand spans across multiple Swizzle Atoms along MN dim, but only one (or partial) Atom along K dim. So given location of Atom x, the hardware needs SBO to know where to load Atom z and others along MN dim. However, LBO is not needed (except non-swizzling cases, not shown in the figure) because for example Atom y is not needed by the MMA instruction in the figure.
From the getCoreMatrixLinearLayout function above, Triton always distributes the Atoms along strided dim first up to a
TMA block.
References
- PTX ISA Documentation v9.3
- Colfax CUTLASS Tutorial: Fast Matrix-Multiplication with WGMMA on NVIDIA® Hopper™ GPUs
- CUTLASS source code for SM100 UMMA descriptors
- Triton source code for NVMMAShared encoding to Linear Layout conversion
Special thanks to Bingyi Zhang from Nvidia! A great amount of details and nuances in this note came from extensive discussions and collaborations with Bingyi.